projects
Diamond Reef Explorers
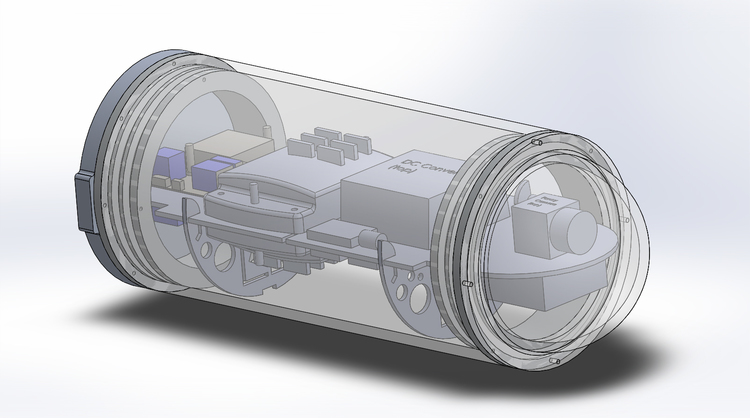
Born out of my insatiable desire to explore the unknown, I wanted to apply my robotics expertise to exploring one of the last great tome of mysteries on our planet– the ocean. To that end, I assembled a team of some of the best engineers I know to create an autonomous underwater vehicle. Rowboat-1, born in Brooklyn, NY, is a robot first tasked with exploring the ocean floor, just off the South Brooklyn coast, in an area once known as the Diamond Reef.
Find out much more about this project at its dedicated site: http://www.diamondreefexplorers.org/
CUDA Laplace Filter
A sample Morphological Laplacian operator (Laplacian of Gaussian) applied to an image using CUDA and OpenCV.
It works by accepting a YUV420p image as input, converting it to RGB, forming a 1D Laplacian of Gaussian kernel, and then performing convolution of that kernel, and its transpose, over all three channels of the image. The results of the two different convolutions are added and the result is displayed.
Rather than looping over the channels of the image, all channels are considered side-by-side during convolution (actually, OpenCV stores the channels interlaced). This offers a considerable speedup.
Typically, with Gaussian kernels, you would perform convolution with a 2D kernel over an image by separating the 2D kernel into Nx1 and 1xN vectors (for separate horizontal and vertical passes). You can do this with any kernel which is separable. However, the Laplacian kernel is not separable and the convolution cannot be performed in this manner. Though you can effectively “separate” (it’s not a real separation) the 2D kernel by adding the results of the convolution of the 1D kernel and its transpose. Adding these results is possible because the Laplacian kernel is a zero sum operator.


ref: https://github.com/Seanmatthews/laplace_filter
ARM (Autonomous Robotic Manipulation)
The DARPA ARM project was a logical extension to the DARPA LAGR project. Where LAGR aimed to push the envelope on autonomous ground navigation, ARM aimed to advance the field in autonomous robotic manipulation, both in hardware and in software. The program was architected as a competition between a number of commerical and educational institutions.
I led two follow-on projects to this program that saw “Robbie the Robot” installed as an interactive exhibit in both the National Museum of American History and the National Air and Space Museum.

In the first museum, the robot played a light-up memory game, the name of which will go unmentioned for legal purposes. After letting visitors control its arm, by moving around an orange ball in its view, to play the game themselves, the robot attempted to beat the visitor’s time. The robot used stereo vision to initially extract the surface of the table from the objects resting on top of it. Image color data, along with a model of the game hardware, allowed the robot to localize the game among those objects. Regional saturation disparities in the image signaled to the robot that a button had been lit. Once the game and its buttons were reconciled within a reference frame common to the robot and all its joints, our motion planner formed a joint trajectory that placed the robots hand above the button to be pressed. Force sensors in the finger joints, coupled with visual data, determined when a button had been pressed. In the interactive version of the game, the robot used its stereo vision to calculate the distance to the orange ball, which it detected with simple color thresholding and ellipse detection.

In the second museum, the robot demonstrated its autonomous perception of the position and orientation of a cylindrical plug, which it then pciked up and inserted into a receptacle on an adjacent wall. Similar methods as above were employed to sense and manipulate the cylindrical plug. Additions to that previous design included:
- Improved fault detection– the installation required the robot to operate without human intervention for upwards of 8 hours per day
- Adequate grasp detection– a statistical model of forces for each hand and finger joint determined the confidence of the grasp on the plug
MAARS
The MAARS is a military “escalation of force” robot, outfitted with a loudspeaker, a laser “dazzler”, a launcher (for beanbags, smoke, teargas, etc), and an assault rifle. Alternatively, that payload may be exchagned for a large arm. I added some minor autonomous behaviors to this vehicle, including waypoint following, obstacle detection, and person following. In order to follow waypoints, the robot estimated its position by fusing local high-precision IMU estimates with global GPS estimates. It employed a standard position PID controller. Front-facing obstacle detection assumed a largely open path and used only sonar sensors to pause the path when encountering an obstacle. Ultrawide-band radio signals aided in person following by trilaterating the distance to the person, and then adjusting velocity.
And just for fun, I made a remote iPhone control for this beast of a vehicle…
BlinkGear
I founded BlinkGear, along with two partners, in 2010. My grandiose idea was to implement “real avatar gaming”, where users remotely control mobile robots through a web-based PC game layer. The gaming layer introduces gaming mechanics, while the real robots offers a tangible experience. We identified three key technologies that this idea would advance: a small and cheap network interface for mobile robot control, efficient video transmission, and a control system that achieves a reactive feel despite potentially-delayed feedback. During the time we dedicated to BlinkGear, we managed to solve the the first of these by creating BlinkRC, the first WiFi-enabled general purpose I/O board of its kind. Here’s BlinkRC featured in Make Magazine:

BlinkGear produced and sold thousands of units, both individual sales and wholesale, over two hardware designs. At some point, the fun had to end.
LAGR
The Learning Applied to Ground Vehicles (LAGR) was a DARPA program intending to push the limits of autonomous ground navigation.LAGR learned autonomous navigation through the classification of different terrain types according to an evaluation of whether they’re traversible.
Follow-on projects involved teaching the robot 1) obstacle and crowd aversion, and 2) human target following. Both tasks used single-scan lidar as the primary means of perception.
Subjugator
Subjugator is a long-standing autonomous underwater vehicle (alongside the similarly named team). Working with a small group of fantastic people at University of Florida, this was my first foray into “real” robotics. This project stoked the embers of my interest in robotics as a lifelong career.

That 2006 AUVSI competition challenged competitors to create a fully-autonomous underwater robot that:
- Travels through a gate (the weed-out task)
- Finds a blinking LED array, noting the color and frequency of the blink sequence
- Follows a “pipeline” toward three bins, differentiated by rim thatching patterns
- Drops a ball bearing into the bin specified by the aforementioned LED sequence
- Surfaces within a floating ring directly overtop an acoustic pinger
My ongoing study of computer vision lent itself to the detection of the pipeline and its orientation, as well as to distinguishing between the three distinct thatching patterns that adorned the bins. After some amount of preprocessing to sharpen, remove artifacts, and binarize the incoming video feed (webcams in 2006 did not perform spectacularly), I applied a Canny edge detector followed by a Hough transform to detect prevalent lines in each frame. A final filtering step on the lines yielded either the orientation of the pipeline, a bin and its descriptor, or nothing. My feature detection approach worked reasonably well, though it temporarily strayed when it caught a linear discoloration at the bottom of the basin. With all of the team’s tremendous contributions, we placed first in the world.